丢失更新¶
概述¶
两个客户端同时对同一个对象(数据库行)执行读取-修改-写入序列,其中一个写操作,在没有合并另一个写入变更情况下,直接覆盖了另一个写操作的结果,所以导致数据丢失(Lost Update)。
快照隔离的一些实现可以自动防止这种异常,而另一些实现则需要手动锁定(SELECT FOR UPDATE)。
发生情景¶
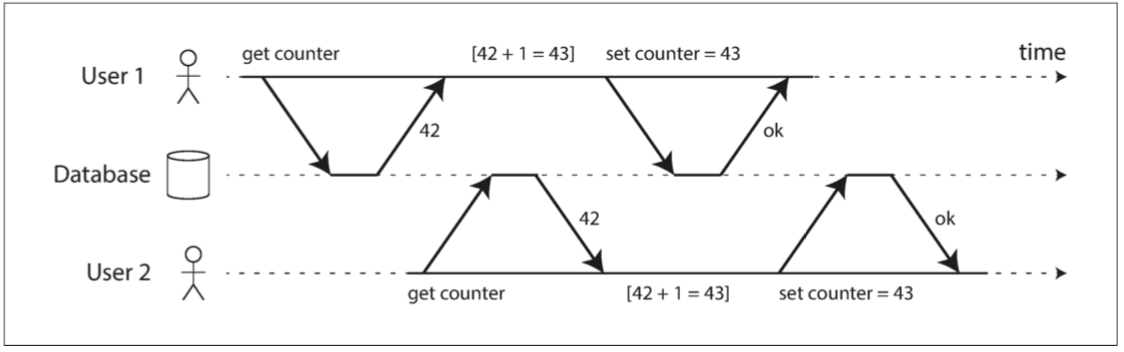
两个客户之间的竞争状态同时递增计数器:
User1 对计数器 +1, User2 也对计数器 +1
User2 后提交,覆盖了 User1 的写入
理论上计数器结果应该是 42+1+1=43, 但目前这种情况的结果是 User2 的提交结果 43
还有其他例子:
更新账户余额(需要读取当前值,计算新值并写回更新后的值)
将本地修改写入一个复杂值中:例如,将元素添加到 JSON 文档中的一个列表(需要解析文档,进行更改并写回修改的文档)
两个用户同时编辑 wiki 页面,每个用户通过将整个页面内容发送到服务器来保存其更改,覆写数据库中当前的任何内容。
防止丢失更新¶
原子写¶
许多数据库提供了原子更新操作,从而消除了在应用程序代码中执行 读取-修改-写入 序列的需要
UPDATE counters SET value = value + 1 WHERE key = 'foo';
原子写的实现方式:
通过在读取对象时,获取其上的排它锁来实现,这种技术有时被称为 游标稳定性(cursor stability)
简单地强制所有的原子操作在单一线程上执行
像 MongoDB 这样的文档数据库提供了对 JSON 文档的一部分进行本地修改的原子操作,Redis 提供了修改数据结构(如优先级队列)的原子操作。
显式锁定¶
FOR UPDATE子句告诉数据库应该对该查询返回的所有行加锁。
BEGIN TRANSACTION;
SELECT * FROM figures
WHERE name = 'robot' AND game_id = 222
FOR UPDATE;
-- 检查玩家的操作是否有效,然后更新先前 SELECT 返回棋子的位置。
UPDATE figures SET position = 'c4' WHERE id = 1234;
COMMIT;
自动检测丢失的更新¶
原子操作和锁是通过强制 读取-修改-写入 序列按顺序发生,来防止丢失更新的方法。另一种方法是允许它们并行执行,如果事务管理器检测到丢失更新,则中止事务并强制它们重试其 读取-修改-写入 序列。
这种方法的一个优点是,数据库可以结合快照隔离高效地执行此检查。PostgreSQL 的可重复读,Oracle 的可串行化和 SQL Server 的快照隔离级别,都会自动检测到丢失更新,并中止惹麻烦的事务。但是,MySQL/InnoDB 的可重复读并不会检测 丢失更新
比较并设置(CAS)¶
-- 根据数据库的实现情况,这可能安全也可能不安全
UPDATE wiki_pages SET content = '新内容'
WHERE id = 1234 AND content = '旧内容';
冲突解决和复制¶
在复制数据库中,防止丢失的更新需要考虑另一个维度:由于在多个节点上存在数据副本,并且在不同节点上的数据可能被并发地修改,因此需要采取一些额外的步骤来防止丢失更新(解决这些冲突)。
多主或无主复制的数据库通常允许多个写入并发执行,并异步复制到副本上,因此无法保证只有一个最新数据的副本,所以基于锁或 CAS 操作的技术不适用于这种情况。
保留多版本,事后合并
这种复制数据库中的一种常见方法是允许并发写入创建多个冲突版本的值(也称为兄弟),并使用应用代码或特殊数据结构在事实发生之后解决和合并这些版本。
原子执行合并
这些写入具有可交换性时(可以在不同的副本上以不同的顺序应用它们,且仍然可以得到相同的结果),可以不关心顺序,原子的执行这些写入。例如,递增计数器或向集合添加元素是可交换的操作。
最后写入胜利
LWW 是许多复制数据库中的默认方案