拓扑排序¶
知识讲解¶
拓扑排序(Topological Sorting):一种对 有向无环图(DAG) 的所有顶点进行线性排序的方法,使得图中任意一点 u 和 v, 如果存在有向边 <u,v>, 则 u 必须在 v 之前出现,对有向图进行拓扑排序产生的线性序列称为满足拓扑次序的序列,简称拓扑排序。
图的拓扑排序是针对有向无环图(DAG)来说的,无向图和有向有环图没有拓扑排序,或者说不存在拓扑排序。
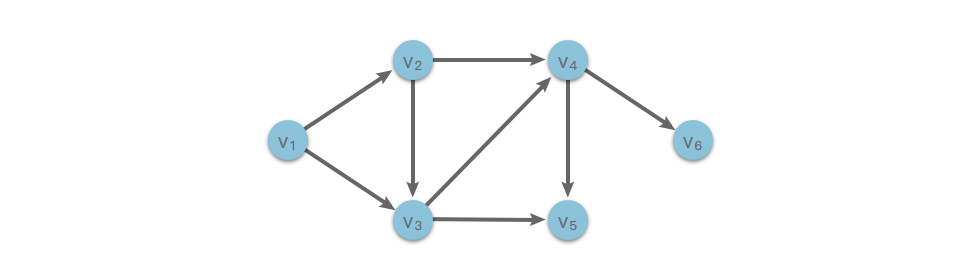
一个图可能存在多个拓扑序列,比如上图的拓扑序列可以是:
\[V_1 \rightarrow V_2 \rightarrow V_3 \rightarrow V_4 \rightarrow V_5 \rightarrow V_6\]
也可以是:
\[V_1 \rightarrow V_2 \rightarrow V_3 \rightarrow V_4 \rightarrow V_6 \rightarrow V_5\]
BFS 实现(Kahn 算法)¶
重要
Kahn 算法主要基于节点的入读进行图遍历,每得到一个入读=0的节点,就得到下一个节点,具体操作如下:
1. 不断找寻有向图中入度为 0 的顶点,将其输出。
2. 然后删除入度为 0 的顶点和从该顶点出发的有向边。
3. 重复上述操作直到图为空,或者找不到入度为 0 的节点为止。
可以看到上述操作其是就是对图进行 BFS 遍历,其关键在于引入队列来暂存入度=0的节点,如果有环,就会发现环里面的节点入度都大于0,也就导致不能完美遍历整个图,也就是排序结果数小于总节点数。
1// 使用 inDegree[i] 维护节点的入读
2// 使用 queue 维护入读为 0 的节点,然后再以 queue 中的节点作为出发点,继续遍历下一层节点
3class Solution {
4 public int[] findOrder(int numCourses, int[][] prerequisites) {
5 // 排序结果指针
6 int resultIndex = 0;
7 // 排序结果容器
8 int[] result = new int[numCourses];
9 // 维护每个节点的入度 inDegree[i]
10 int[] inDegree = new int[numCourses];
11 List<List<Integer>> edges = new ArrayList<>();
12 for (int i = 0; i < numCourses; i++) {
13 edges.add(new ArrayList<>());
14 }
15 for (int[] it : prerequisites) {
16 edges.get(it[1]).add(it[0]);
17 inDegree[it[0]]++;
18 }
19 Queue<Integer> queue = new ArrayDeque<>();
20 for (int i = 0; i < numCourses; i++) {
21 if (inDegree[i] == 0) {
22 // 入度为 0 的节点加入队列和最终结果
23 queue.add(i);
24 result[resultIndex++] = i;
25 }
26 }
27 while (!queue.isEmpty()) {
28 // queue 维护入读为 0 的节点, 删除入度为 0 的 vertex
29 Integer vertex = queue.poll();
30 // 访问 vertex 的下一层
31 for (Integer next : edges.get(vertex)) {
32 // 删除 vertex 后,相连的节点入读就需要减 1
33 inDegree[next]--;
34 if (inDegree[next] == 0) {
35 // 入度为 0 的节点加入队列和最终结果
36 queue.add(next);
37 result[resultIndex++] = next;
38 }
39 }
40 }
41 // 这里很重要,只有排序结果数和节点数想等,才说明没有环,当前图存在一个拓扑排序
42 return resultIndex == numCourses ? result : new int[0];
43 }
44}
DFS 实现¶
重要
基于 DFS 实现拓扑排序算法的基本思想:
对于一个顶点 u,深度优先遍历从该顶点出发的有向边
<u,v>:如果从该顶点 u 出发的所有相邻顶点 v 都已经搜索完毕,则回溯到顶点 u 时,该顶点 u 应该位于其所有相邻顶点 v 的前面(拓扑序列中)。
这样一来,当我们对每个顶点进行深度优先搜索,在回溯到该顶点时将其放入栈中,则最终从栈顶到栈底的序列就是一种拓扑排序。
DFS 遍历的一个重点是一边遍历,一边使用 visited[] 标记节点状态(0-未访问 1-遍历中 2-遍历完毕),如果 有环,那么深度优先遍历从该顶点出发的有向边时,就会发现有节点已经被标记为 遍历中
1class Solution {
2 int resultIndex; // 配合 result 数组模拟栈
3 int[] result; // 栈,保存拓扑排序结果
4 int[] visited; // 用来标记访问状态(访问当前节点所有相邻节点) 0-未访问 1-访问中 2-访问完
5 boolean valid = true; // 标记是否有环
6
7 public int[] findOrder(int numCourses, int[][] prerequisites) {
8 resultIndex = numCourses - 1;
9 result = new int[numCourses];
10 visited = new int[numCourses];
11 List<List<Integer>> edges = new ArrayList<>();
12 for (int i = 0; i < numCourses; i++) {
13 edges.add(new ArrayList<>());
14 }
15 for (int i = 0; i < prerequisites.length; i++) {
16 int[] it = prerequisites[i];
17 edges.get(it[1]).add(it[0]);
18 }
19 for (int i = 0; i < numCourses && valid; i++) {
20 if (visited[i] == 0) {
21 dfs2(edges, i);
22 }
23 }
24 return valid ? result : new int[0];
25 }
26
27 public void dfs2(List<List<Integer>> edges, int vertex) {
28 // 将当前节点标记为 访问中
29 visited[vertex] = 1;
30 // 深度优先遍历从该顶点出发的有向边
31 for (Integer next : edges.get(vertex)) {
32 if (visited[next] == 0) {
33 dfs2(edges, next);
34 } else if (visited[next] == 1) {
35 // cycle
36 valid = false;
37 return;
38 }
39 }
40 // 从该顶点 vertex 出发的所有相邻顶点都已经搜索完毕
41 result[resultIndex--] = vertex;
42 // 将当前节点标记为 访问完
43 visited[vertex] = 2;
44 }
45}