Elastic Stack 介绍
总体介绍
Elastic Stack 构建在开源基础之上,Elastic Stack 让您能够安全可靠地获取任何来源、任何格式的数据,并且实时地对数据进行搜索、分析和可视化。官方网站:https://www.elastic.co/cn/products/
Beats 系列
Beats系列包含全品类采集器,可以搞定几乎所有数据类型。每款开源 Beat 都以 libbeat(转发数据时所用的通用库)为基石,当我们需要监控某个专用协议,可以在 libbeat 之上自行构建 beat。
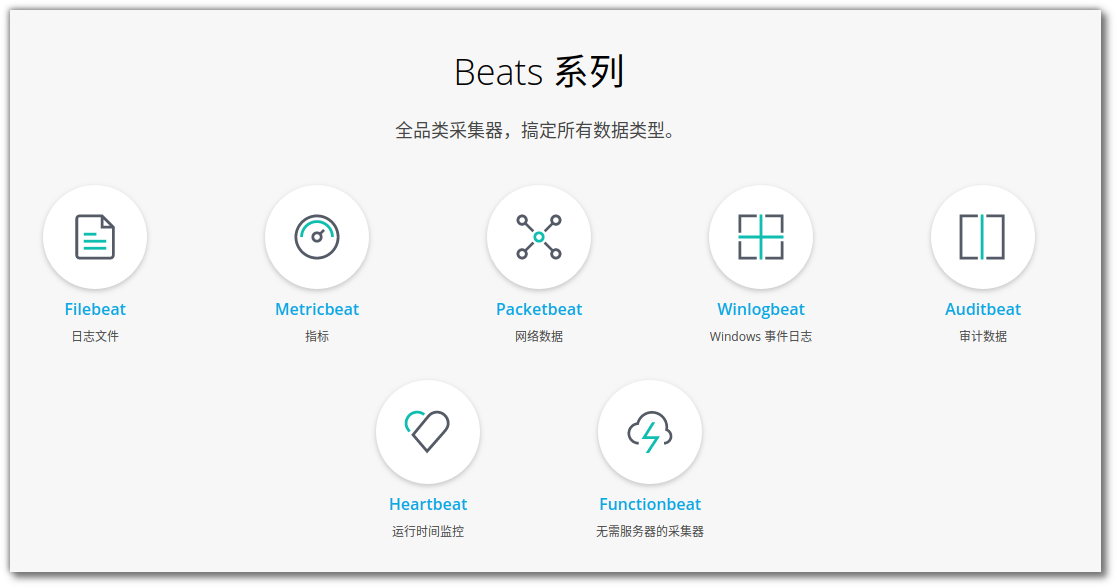
总体设计
每一个应用实例都会产生一个日志文件,假设每一个应用实例都部署在不同的服务器上(虚拟机/容器),那么每台服务器都需要部署一个 filebeat 来实时搜集应用实例增量产生的日志,filebeat 将增量日志发送到消息队列中供 Logstash消费,Logstash对消息进行处理之后发送到 Elasticsearch中,再部署一个Kibana对 Elasticsearch中的日志进行可视化查询与统计。
filebeat 部署指南
filebeat 介绍
filebeat 是一个部署在服务器上的日志搜集器,可以监控指定文件内容的变化,转发文件的增量内容到消息队列、Logstash、Elasticsearch。
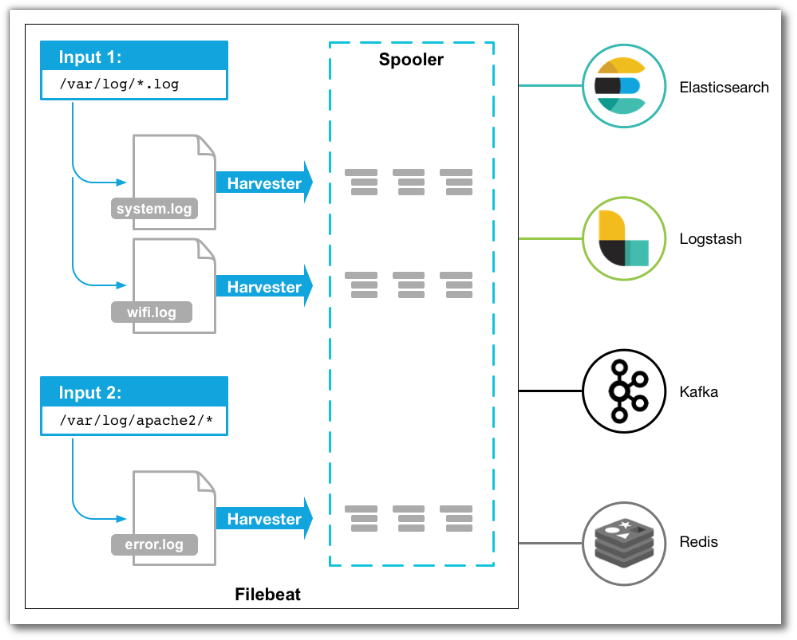
当filebeat启动的时候,它会检索配置文件所配置入口,然后为每一个文件启动一个 harvester,每一个harvester都会读取对应的日志文件中的增量内容,并将其发送到libbeat,libbeat会将这些内容聚集在一起发送到filebeat配置的出口。
filebeat 安装
deb:
1 | curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.1-amd64.deb |
rpm:
1 | curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.1-x86_64.rpm |
mac:
1 | curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.1-darwin-x86_64.tar.gz |
linux:
1 | curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.0.1-linux-x86_64.tar.gz |
filebeat 配置
1 | # filebeat 的输入, 每一个 - type 可以定义一个输入类型 |
filebeat使用
启动与关闭
1 | # 启动 |
filebeat 启动之后会有守护进程保障其安全稳定的运行,因此直接kill filebeat的进程是不能停止filebeat的,必须使用服务的方式停止。
状态查看
1 | systemctl status filebeat.service beat -l |
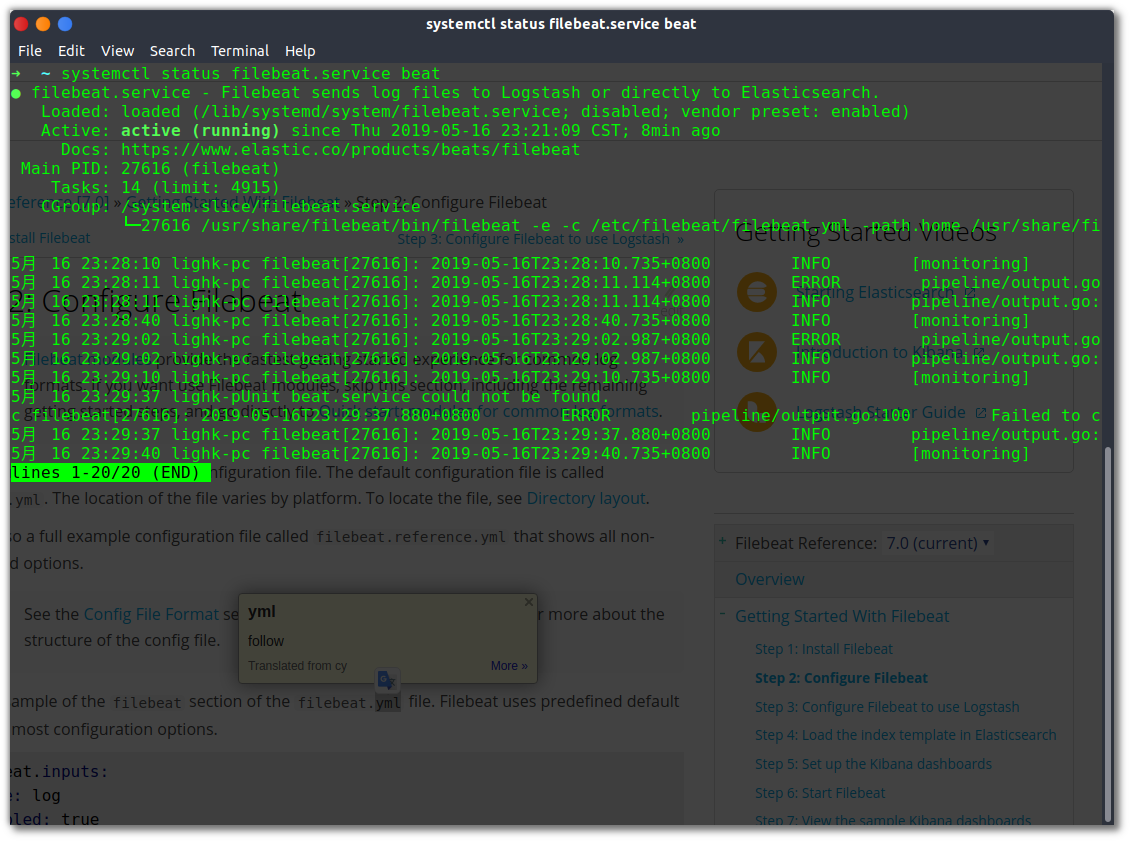
可以看到 Active:的状态是 running,表明filebeat已经正常启动,同时也可以看到最新搜集到的日志内容;当配置文件没有正确配置的时候,使用这个命令也可以查看出错误提示信息。
Logstash部署指南
Logstash 介绍
Logstash 是开源的服务器端数据处理管道,能够:
- 同时从多个来源采集数据
- 转换数据
- 然后将数据发送到您最喜欢的 “存储库” 中。
输入——采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。 Logstash 支持 各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
过滤器——实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 简化整体处理,不受数据源、格式或架构的影响
Logstash的过滤器库丰富多样,拥有无限可能。
输出——选择您的存储库,导出您的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
Logstash 配置
1 | input { |
如果有多个数据来源,可以使用 tag 来标识,使用 grok 进行过滤的时候再判断,依据不同的tag 做不同的处理,如下所巨之例:
1 | input { |
再部署调试阶段,如需要将接收到的内容实时的输出到控制台,只需要在 output 中加标准输出,具体如下:
1 | output { |